author
Pavel Larionov
The pace of AI breakthroughs nowadays might seem spontaneous, but it’s actually the result of very profound work of numerous research groups around the globe, developing algorithms and approaches. Every new feature and AI-powered product is a mix of those algorithms, chained together, manipulating large numbers and dimensions to create an animated image of a cute cat for us. Involving AI on every step of those processes is currently expensive and not always efficient, that is why a seamless integration of AI with traditional algorithms represents the necessity to balance the versatility of AI models with the robustness of classic computing. This way, the currently unstable nature of generative AI is balanced and double-checked, making the solution truly bullet-proof and production-ready. Those businesses and creatives who will understand what model to use where, what is a job for AI and what isn’t, will survive the age of disruptive AI.
In this exploration, we dive deep into the mechanisms and applications of the so-called Composite AI approach, drawing parallels with established methodologies and examining real-world implementations that showcase this synergistic approach.
OpenAI is still on the forefront of the AI revolution. Their core team consists of highly talented and renowned machine learning specialists. That said, much of their technology relies on very sophisticated integration of foundational frameworks and algorithms, created by many companies and researchers throughout the past decades. Some examples:
Those algorithms in their turn, are based on mathematical principles discovered sometimes centuries ago, as for example latent space conversion, which can be traced back to statistics works from the early 20th century.
Without any doubt, since it’s foundation, OpenAI created numerous algorithms and pipelines themselves:
So by no means the progress we celebrate came out of nowhere. But we needed a company, which would be able to put all pieces of the puzzle in place.
While ChatGPT platform exemplified how powerful technologies can be, when applied correctly, we are stepping into the next phase of the AI revolution with generative videos now, as OpenAI introduced Sora.
On the surface, Sora is yet another video creation platform, which we have seen throughout 2023 – Runway being one of the most prominent examples. Under the hood, OpenAI calls Sora “an important step towards AGI (artificial general intelligence)”. Let’s shortly discuss why.
Technologically, we see that Sora is built from those bits and pieces, which we have mentioned earlier:
The most fascinating thing about Sora is its emergent properties, which only appear when you apply those technologies on an enormous, internet-size scale.
We saw those emergent properties in GPT, when the model was able to derive answers based on context and “reason” on topics, which never came up in the body of the training data, which makes users (and some researchers and developers) believe that GPT actually can think.
Now we are about to witness a similar kind of excitement with generated videos, as in order to produce plausible videos, the model must be able to reproduce basic sequences of actions and reactions.
We have started our outlook with the visions of Sora, the new OpenAI video generating algorithm. If you have read our previous article about spatial computing, you probably can recall the Gaussian splatting technique. If not – we encourage you to read it, but in short, Gaussian splatting is a method to convert a series of images of an object, made without any special equipment, into a 3D object, importable into 3D editors like Blender and further into game engines like Unreal or Unity. In the same article, we also made an example of how this technique can work by having screenshots from virtual worlds (e.g. recreating virtual objects from a video game) or using frames from a video (e.g. from drone) as input.
You can probably already guess what we are getting to.
On the video above:
Yes, you can combine Sora (which is itself a combination of different AI techniques) and another machine learning method – Gaussian splatting – to make 3D objects based on videos produced by Sora. So it’s a full-cycle digital production, which doesn’t require any photo-video equipment, doesn’t require any 3D modeling or sketching, and which can get you from having the craziest idea to implementation of that idea into a 3D object for your virtual experience or video game or anything in between.
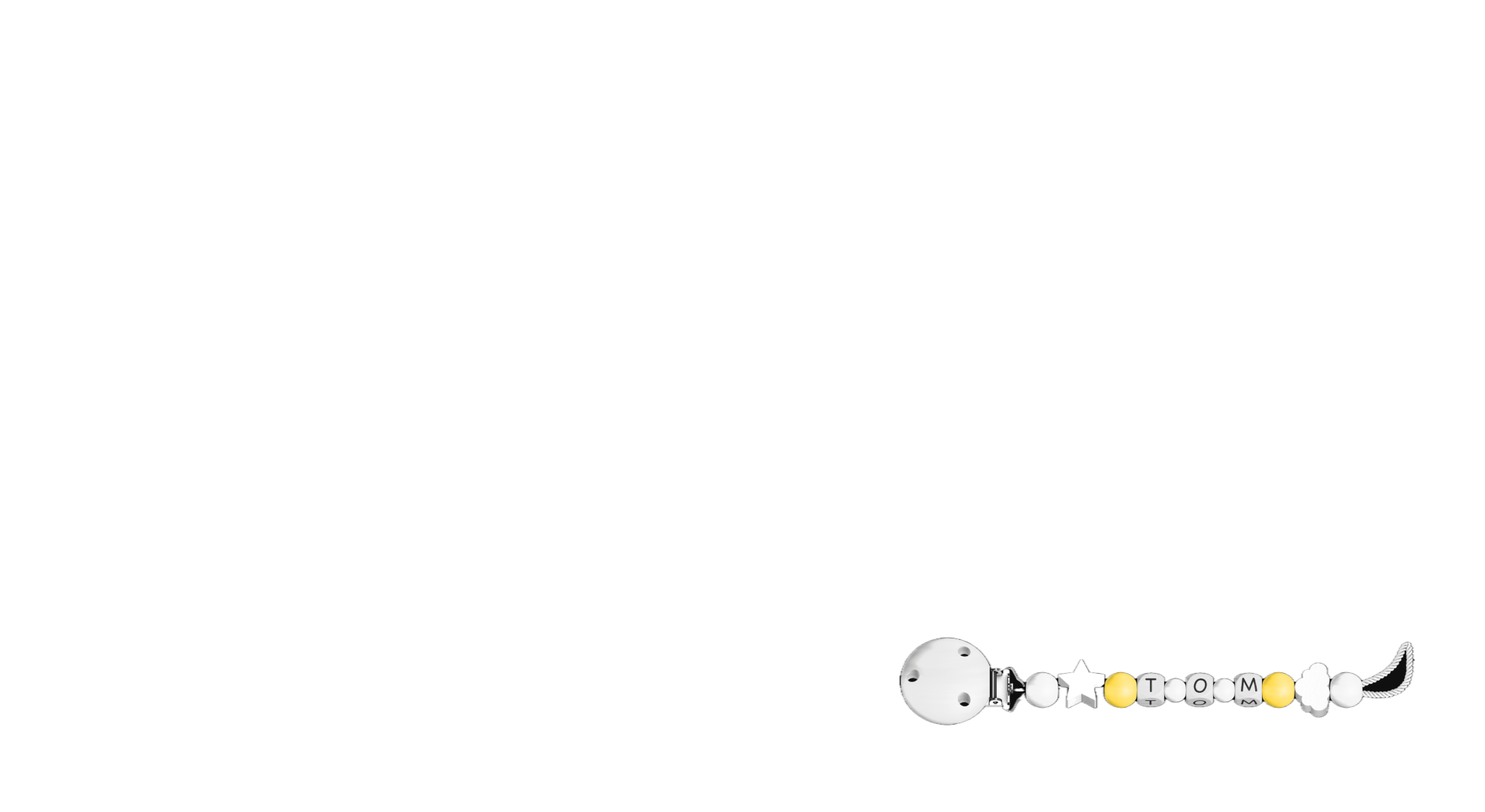
Recently we have created an intelligent customization tool for a company who produces pacifier chains. Let’s take this problem as an example and break it down in order to understand how we solved it.
The configurator features lots of beads to select from. The buyers won’t want to scroll through them all and probably not everyone would know where to start.
We could probably program some kind rule-based algorithm, which would have nested “ifs” and “elses”, while considering the color theory and asking the user multiple questions, but first, nobody likes answering questions in forms and second – we are innovation company, so why not use AI?
So we decided to let users just enter their prompt freely in a field. And our AI would do the heavy lifting of coming up with beads, matching colors and trying it’s best to make it fit to the described child.
The inputs must not be exact (like colors or shapes). Buyers can vaguely describe what are the topics or interests they would like the chain to feature and the AI would match it to what’s available in the store.
First of all, we have processed the positions of the shop themselves with AI to bring it to a format we required.
Then we started implementing the front- and backend flow:
The buyer can try again or edit certain parts of course. You can try it yourself here: schnullerkette.de
In conclusion, the composite AI approach has the potential to revolutionize various industries and domains. By combining the strengths of different AI technologies and traditional algorithms, we can create solutions that are more powerful, efficient, and accurate, while still being affordable. However, it is essential to have a good understanding of how AI technologies work, acquire hands-on experience in applying them, and realize their limitations. By leveraging the strengths of AI and compensating for its weaknesses, we can unlock new possibilities and drive innovation across multiple sectors.
At Hyperinteractive, we are lucky to possess all necessary components for a successful implementation of intelligent solutions of high complexity. We have various solutions in our portfolio, for example Dot Go – an app for visually impaired or our relationship coach Eric AI.
Your business also needs AI? Let’s talk!
We are working on intelligent solutions since 2017. We are experienced with custom solutions as well as all the tools AI. These are just three example cases.

